- Published on
Optimizing Healthcare AI Models with Intel's OpenVINO
- Authors
- Name
- Nathan Peper


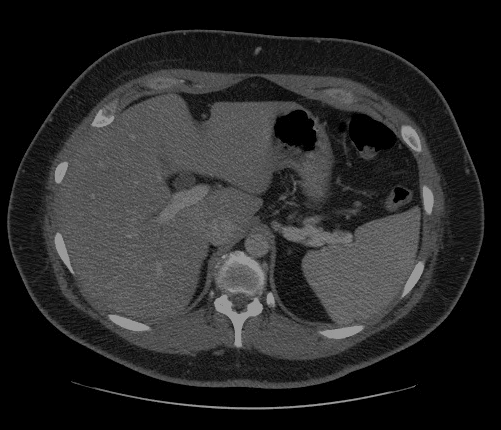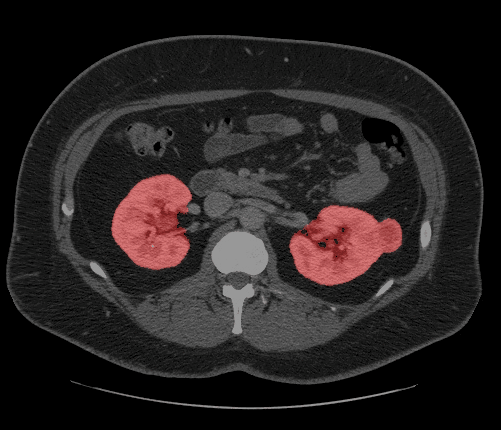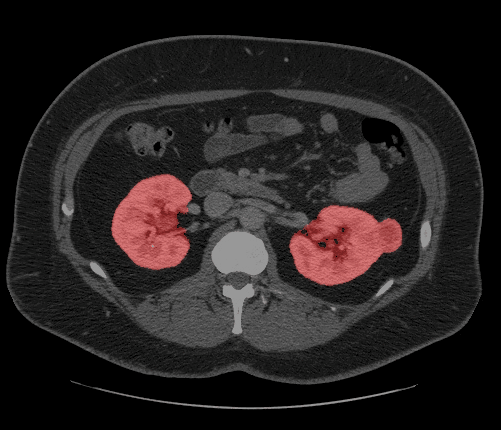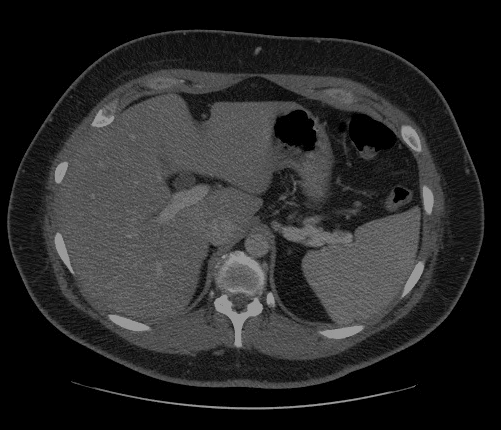
Introduction
In recent years, the healthcare industry has witnessed a transformative shift towards the adoption of Artificial Intelligence (AI) and Data Science to improve patient outcomes, optimize processes, and reduce costs. As the complexity of AI models increases, so does the demand for efficient and scalable optimization techniques. This overview aims to guide Data Science and AI practitioners in the healthcare industry on how to leverage the power of Intel's OpenVINO (Open Visual Inference & Neural Network Optimization) to optimize their AI models, resulting in enhanced performance, reduced inference time, and increased ability to deploy models across various healthcare settings.
Understanding Intel's OpenVINO
Intel OpenVINO is an open-source toolkit designed to optimize deep learning models for various edge devices, including CPUs, GPUs, FPGAs, and VPUs. The primary focus of OpenVINO is to improve inference performance by leveraging advanced model optimization techniques such as quantization, model compression, and hardware-specific optimizations. For healthcare applications, where real-time analysis and low latency are crucial, integrating OpenVINO can be a game-changer.
Challenges in Healthcare AI Models
Healthcare AI models often encounter challenges due to their complexity and resource-intensive nature. Some of the common challenges include:
- Large Model Sizes: AI models in healthcare may have millions of parameters, making them unsuitable for deployment on resource-constrained edge devices.
- High Inference Latency: Traditional AI models might have slow inference times, which can impede real-time decision-making in critical healthcare scenarios.
- Data Privacy and Security: Healthcare data is sensitive, and maintaining privacy and security is paramount when deploying AI models in a healthcare setting.
Leveraging OpenVINO for Healthcare AI Optimization
Getting started with OpenVINO has never been easier as the developer team has produced many tutorials and getting started guides for many industry applications. You can quickly the breadth of options available by checking out the various Jupyter Notebook tutorials.
Across these notebooks there are a number of examples leveraging various optimization techniques across all of the popular frameworks, such as PyTorch, TensorFlow, ONNX, etc. Some of these foundational and more advanced capabilities include:
- Model Quantization: OpenVINO offers various quantization techniques like Post-training Quantization and Quantization-aware training. These methods reduce the model's precision without significant loss in accuracy, thereby reducing the model size and improving inference speed.
- Model Compression: Techniques like pruning, where less important model parameters are removed, and knowledge distillation, where a smaller model learns from a larger model, can significantly reduce the model size and enhance performance.
- Hardware-specific Optimizations: OpenVINO enables practitioners to take advantage of hardware-specific optimizations for Intel CPUs, GPUs, FPGAs, and VPUs. This optimization can lead to substantial performance gains on specific Intel hardware.
- ONNX Support: OpenVINO supports the ONNX (Open Neural Network Exchange) format, allowing seamless conversion of models from popular frameworks like TensorFlow and PyTorch.
- Data Privacy and Security: OpenVINO ensures data privacy and security by allowing the deployment of models without exposing the underlying architecture or weights.
For a quick introduction to see how OpenVINO is used to accelerate medical imaging in healthcare, checkout the "Quantize a Segmentation Model and Show Live Inference" notebook.
Step-by-Step Optimization Process
- Model Selection: Choose a pre-trained or custom-trained model that best suits your healthcare application's requirements.
- Model Conversion: Convert the model to an intermediate representation using the OpenVINO Model Optimizer. This step allows the model to be optimized for the target hardware.
- Quantization and Compression: Apply quantization and compression techniques to reduce model size and enhance inference speed while monitoring any impact on accuracy.
- Hardware-specific Optimization: Utilize OpenVINO's hardware-specific optimization capabilities to further enhance performance on Intel hardware.
- Benchmarking and Evaluation: Measure the optimized model's inference speed and compare it against the baseline model to validate the improvements achieved through OpenVINO.
- Deployment and Monitoring: Deploy the optimized model in your healthcare application and monitor its performance in real-world scenarios.
Conclusion
Data Science and AI practitioners in the healthcare industry can unlock the full potential of their AI models by leveraging Intel OpenVINO for model optimization. By reducing model size, enhancing inference speed, and ensuring data privacy, OpenVINO empowers healthcare applications with real-time, efficient, and secure AI capabilities. As the demand for AI in healthcare continues to grow, integrating OpenVINO will prove to be an invaluable asset for improving patient care and advancing medical research.
Remember, innovation in healthcare AI relies on a combination of powerful algorithms, efficient hardware, and ethical considerations, and Intel OpenVINO plays a pivotal role in achieving this synergy. So, embrace the power of OpenVINO and revolutionize healthcare AI for a healthier and brighter future. And as always, if you have questions or want to speak to someone from the Health and Life Sciences team at Intel, you can always contact health.lifesciences@intel.com.